La plupart du temps, les scripts servent à extraire d'un fichier HTML (une page Web), un XML exploitable par des XPath afin d'obtenir les données désirées. Ici, nous allons faire un exercice simple, qui ne fait appel qu'à une seule donnée. Elle s'affichera dans un Capteur HTML, pour aller plus loin il faudra savoir extraire des données limitées par les mêmes tags (Voir dans le menu général à la fin des trucs et astuces PHP)
On va être ambitieux, on va aller récupérer le bulletin simplifié Météo-France du jour on va voir les étapes nécessaires et au final comment en faire un périphérique pour Eedomus
http://www.meteofrance.com
Mais... mais il ya un hic, ce serait trop simple... on va sur cette page repérer les mots clefs, notamment les premiers mots de ce bulletin simplifié et après avoir fait "bouton droit" puis "afficher le code source", on va faire une recherche (Ctr-F) et être surpris de ne pas les trouver ! En fait, cette page appelle des variables,
<a data-bypass="" href="/previsions-meteo-france/bulletin-france"> Lire la suite </a>
Mais c'est justement ce qu'on désirait : le mini-bulletin
NB: Ceci se trouve assez facilement en examinant le code source et en s'aidant des outils des navigateurs "analyser l'élément" (bouton droit) qui nous donneront le contenu de la variable, mais surtout sa position.
NB: de temps à autre il faut s'attendre à ce qu'une page HTML change, c'est le cas ici, la page Meteo-France est devenue utilisable pour extraire les données de micro-météo et l'alternative Orange se bloque sur une date antérieure (non mise à jour)... L'important ici est de comprendre le principe, pour l'utilisation en condition réelle, il faudra s'adapter et corriger les scripts en fonction des changements de sources... Si vous suivez les didacticiels, ce ne sera pas difficile, si vous vous contentez de recopier sans les comprendre les scripts, ça ne fonctionnera pas toujours... et c'est bien normal : un didacticiel, c'ets fait pour apprendre, pas à utiliser sans comprendre...
=====
EDIT : les pages ayant encore changé, le code actif se trouve dans l'addentum, on notera une commande supplémentaire décrite dans la partie PHP, le DotAll "s". puisque le code à rechercher après l'info est coupé par un retour ligne (d'où le DotAll) et des tabulations (d'où les caractères de remplacement ".*"
De plus l'info sommaire du bulletin est prise maintenant dans le premier "Slide" de la page principale.
Tout est compréhensible si vous comprenez l'exemple ci-dessous qui n'est plus valide, uniquement à cause du bug non corrigé depuis des mois de la page météo d'Orange qui persiste à mettre en avant... l'info commaire météo du vendredi 5... juin. (?).
=====
https://meteo.orange.fr/
Cette fois-ci, nous avons bien le texte dans le code source que nous allons maintenant examiner.
NB : Pour nous simplifier le travail, on recherche toujours des alternatives quand elles sont possibles ! donc de manière générale, quand on se retrouve avec différentes sources, on prend la plus simple. Cela peut arriver avec des passerelles dont plusieurs marques peuvent se partager la même technologie, mais ayant chacune ses propres espaces de données (ex. Mobile Alerts).
<div class="vigilance-bulletin-status">
<strong>
Aujourd’hui dimanche 17:
</strong>
<br>
<strong>
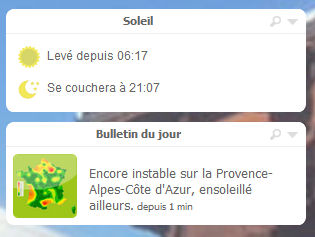
Encore orageux sur la Provence-Alpes-Côte d'Azur, ensoleillé ailleurs.
</strong>
</div>
NB: on a rajouté des retour ligne pour la clarté, mais quand on copie/colle des parties de code, il ne faut bien sur pas les prendre en compte.
function httpQuery($url) {Ne testez rien pour l'instant (il n'ya pas de code encore)
// coller dans l'espace libre ci dessous le code source de la page HTML appellée
$return=<<<'pageHTML'
pageHTML;
return $return;
}
Il va falloir "découper" ce code pour n'en extraire que ce qui nous interresse, c'est à ce moment seulement qu'on testera notre code qui commencera donc par:
// récupération de tout le code source
$url = "https://meteo.orange.fr/";
$url = httpQuery($url,'GET');
<div class="vigilance-bulletin-status"><strong>
et se termine, après les données à extraire par :
</strong></div>
On fait une recherche après avoir collé le code dans Notepad++ (en général, avant de coller, on laisse à UTF8 et on choisis langue = HTML, puis on enregistre) du code de début : BINGO, il est tout seul, cela nous arrange, maintenant on fait de même avec le code de fin : reBINGO, décidémment, on a de la chance, puisque cette séquence est aussi unique (l'important ici c'est surtout qu'il n'y en ai pas avant le code de début), cela va devenir assez simple de sélectionner cette partie:
Nous allons utiliser les Regex et donc une expression Regex, ici preg_replace() qui se trouve dans la liste des fonctions autorisées. Maintenant que vous êtes allé voir le lien explicatif, avançons:
On est SUR qu'il y a quelque chose avant, dedans et après les données cherchées, donc on va supprimer:
$url = preg_replace('#.*<div class="vigilance-bulletin-status"><strong>|</strong></div>.*#s',"",$url);Maintenant on peut contrôler: dans le bac à sable, on colle ce code à la suite du code httpQuery, suivit de quelques espaces pour le compléter puis d'un echo et pour terminer un tag de fin de code php :
echo $url;On obtient: ce résultat:
?>
Aujourd'hui dimanche 17:</strong><br /><strong>Encore orageux sur la Provence-Alpes-Côte d'Azur, ensoleillé ailleurs.
$url = preg_replace("#.*</strong><br /><strong>#","",$url);Encore orageux sur la Provence-Alpes-Côte d'Azur, ensoleillé ailleurs.
Il reste à délimiter le code avec des balises pour faire un XML :
$url = "<bulletin>" . $url . "</bulletin>";Copiez la partie code, avec les tags php, enregistrez avec une extension php (bulletin.php par exemple) et enregistrez ce php dans votre dossier script.
Voila, notre code est terminé, il s'appellera avec ... un "capteur HTTP" que vous connaissez déjà (le même que pour le script heure.php) Vous n'avez qu'à indiquer l'appel :
http://localhost/script/?exec=bulletin.phple XPath
//bulletinle nom, la pièce, l'usage (autre), le type (texte), et la fréquence de capture (quelques heures) en mn.